Research
Overview
Our laboratory formulates, examines, and develops algorithmic solutions to a wide spectrum of problems of fundamental interest involving the manipulation of signals and information in diverse settings. Our work is strongly motivated by and connected with emerging applications and technologies.
In pursuing the design of efficient algorithm structures, the scope of research within the lab extends from the analysis of fundamental limits and development of architectural principles, through to implementation issues and experimental investigations. Of particular interest are the tradeoffs between performance, complexity, and robustness.
In our work, we draw on diverse mathematical tools—from the theory of information, computation, and complexity; statistical inference, learning, and artificial intelligence; signal processing and systems; coding, communication and networks—in addressing important new problems that frequently transcend traditional boundaries between disciplines.
In addition to RLE, we are affiliated with the Computer Science and Artificial Intelligence Laboratory (CSAIL), with which we have joint projects and close collaborations, and the Schwarzman College of Computing. We also collaborate with faculty, staff, and students involved with the Institute for Data, Systems, and Society (IDSS) and the Laboratory for Information and Decision Systems (LIDS), as well as other entities on campus.
Much of our activity has centered around a variety of different types of problems arising naturally in the context of embedded processing in systems, networks, and applications.
Current Interests
Some of the topics of current interest include:
- information theory, algorithms, and architectures for machine learning and high-dimensional statistical inference
- theory, algorithms, and technologies for optical sensing, computational imaging, and computer vision
- inference, control, and monitoring aspects of unmanned and autonomous vehicles
- machine learning techniques for efficient databases and storage
- artificial intelligence techniques for RF spectrum analysis and interference suppression, and applications
- data-driven machine learning methods for audio and underwater acoustic signal processing
- new applications of machine learning
- fundamental limits of energy-efficient, error-resilient nanoscale systems, and enabling designs
- coding and inference aspects of neuroscience, and computational and systems biology
- new classes of codes, and decoding algorithms, particularly for new applications
Examples of older research investigations
Some representative older research investigations are described below. For more recent investigations, browse some of the publications in recent years.
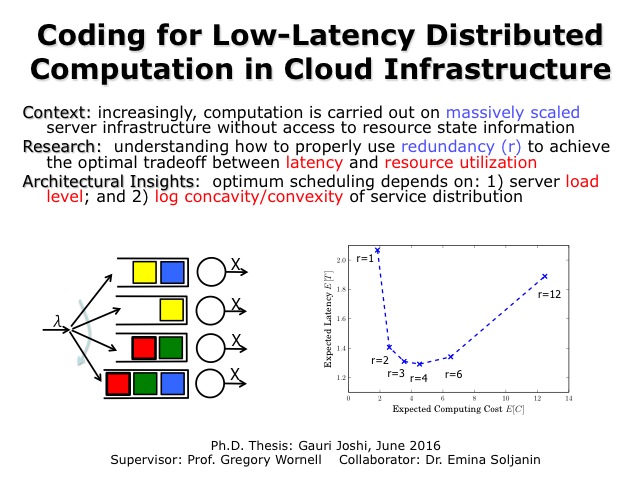
Coding for Low-Latency Distributed Computation in Cloud Infrastructure
Gauri Joshi, Emin Soljanin, and Gregory W. Wornell
An increasing amount of computation is being carried out on massively scaled distributed “cloud” server infrastructure. In practice, there are significant variations in how long a particular machine takes to execute a given task within a larger job. However, the risk of very slow job completion times can be avoided through redundant execution of tasks, analogous to the use of error-control coding in communication systems. Despite the growing use of such infrastructure, there has been comparatively little analysis to guide system designers. In this work, we analyze the fundamental tradeoff between execution time (job latency) and machine time (redundant execution) in such systems, focusing on protocols that avoid the need for resource state information. Our analysis reveals important new principles for the design of systems that approach these limits. Among other results, we show that there are two distinct behavior regimes, corresponding to the log-convexity or log-concavity of the task service distribution. In the former regime, we show that a protocol with maximum redundancy is most effective, while in the latter regime, a protocol with less redundancy and an early cancellation policy is most effective.

An Architecture for Low-Power Voice-Command Recognition
Qing He, Wei Ma, and Gregory W. Wornell
Voice recognition has become an essential technology for mobile devices with the advent of digital assistants, and is expected to be more important still in wearable electronics of the future. However, energy consumption of current technologies is a key impediment to such future systems. In this research, we develop an ultra-low power voice-command recognition technology that addresses these challenges. Key to our solution are the following ingredients: efficient analog-domain feature pre-selection, very low rate analog-to-digital conversion via multi-coset sampling, and adaptive digital feature post-selection using a novel, low-complexity multi-band deep neural network architecture. Our prototype, implemented via a TI Cortex-M0 micro controller, consumes a remarkably small 230 microwatts, while making recognition decisions every 40 milliseconds. This work is an example of the growing role for embedded inference and learning in future systems, and the importance of careful hardware-software co-design in obtaining resource efficient solutions.
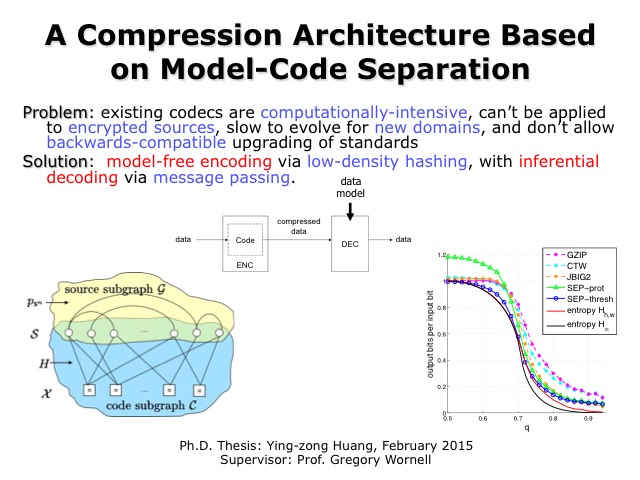
A Compression Architecture Based on Model-Code Separation
Ying-zong Huang and Gregory W. Wornell
Compression technologies for video, images, audio, and other forms of data play a critical (and often embedded) role in today’s ubiquitous modern digital systems, software, and infrastruture. However, new compression technologies and codecs are required to meet the needs of emerging applications and platforms. In particular, there is a growing need a new generation of compression codecs that: 1) allow the traditional standardization bottleneck in compression development to be circumvented, to accelerate technology evolution; 2) allow for the rapid development of domain-specific compression technology for diverse, emerging communities; 3) support compression in the encrypted domain without requiring access to the key; and 4) are well matched to implementation on low-power mobile devices and distributed sensors. To meet these requirements, we have developed a new, practical, and general compression architecture that does not require the encoder to know the source model to achieve compression arbitrarily close to fundamental limits dictated by the entropy rate. The encoder is extremely simple to implement, and is combined with an novel inferential decoder that uses a fast, efficient message-passing algorithm in the form of belief-propagation to reconstruct the source from the compressed bits and the source model. Beyond its practical benefits, this work emphasizes the increasingly important connections between compression, statistical inference, and learning.

Sparse Multi-Coset Antenna Array Architecture for Efficient Imaging
James Krieger, Yuval Kochman, and Gregory W. Wornell
With recent advances in hardware technology, including terahertz CMOS circuits, there is the potential to develop low-cost, high-resolution coherent imaging systems for a host of applications. However, a significant remaining challenge is the large number of antenna elements typically required to construct a digital phased array in such applications. As an example, a 100 GHz vehicle collision avoidance system with a 2m x 0.2m aperture would require roughly 100,000 elements. Since both the complexity of calibration and the processing requirements scale with the number of antenna elements, such a system would be daunting to implement. Traditional approaches to this problem either produce false images, reduce signal quality or resolution, or limit the digitally achievable field-of-view. In this work, we develop a new sparse antenna architecture based on the use of multi-coset arrays in which elements are spaced in a recurrent nonuniform pattern. We show that through the use of such arrays, it is possible to reconstruct scenes using an array density only proportional to the scene density. In practice, this leads to a substantial reduction in the number of elements required for imaging. The signal processing we develop for this application consists of two stages: 1) a novel soft-decision version of the classical MUSIC algorithm identifyies where a scene has content; and 2) an efficient least squares algorithm is employed to reconstruct the identified content to the full resolution dictated by the array aperture. We further develop a methodology for the design of good universal multi-coset array patterns, and a robust algorithm for reliably detecting when the array density is insufficient to reconstruct the scene of interest. Our simulations and experiments reveal that this new architecture can reduce the number of antenna elements required in the system by an order of magnitude or more per dimension.
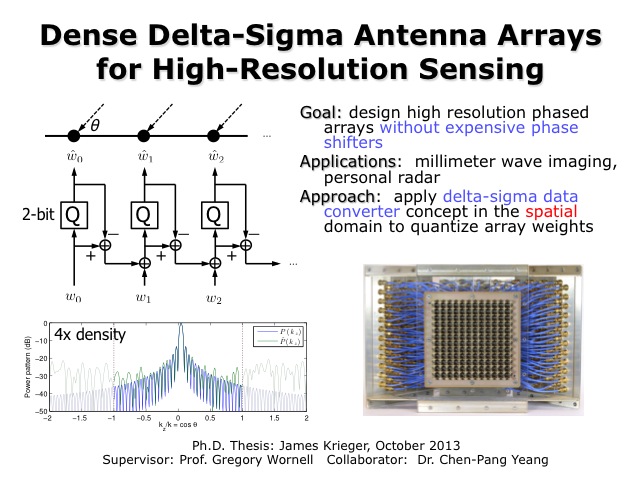
Dense Delta-Sigma Antenna Arrays for High-Resolution Sensing
James Krieger, Chen-Pang Yeang, and Gregory W. Wornell
Phased arrays have long been recognized as an attractive, high-performance antenna technology, and have the convenient property that the resulting antennas can be steered electronically instead of mechanically. Such steering is accomplished by adjusting the phases at each of the constituent antenna elements in the array forming the aperture. However, accurate steering has traditionally required high-resolution phase shifters, which are expensive. Such cost considerations have precluded the of phased arrays in many applications. In this work, we develop a new phased array architecture that obviates the need for such precise phase shifters. In this architecture, the aperture is populated with antenna elements spaced more finely than the familiar half-wavelength convention would otherwise dictate, and resulting dense array is used in conjunction with novel spatial domain delta-sigma signal processing. Using analysis that takes into account the effects of quantization and mutual coupling, we characterize the performance of such arrays in terms of the tradeoff between signal quality and power transfer efficiency. As an illustration of performance potential, we show, using simple two-bit phase shifters and a practical impedance matching network, that a four-fold increase in the array density provides a roughly 6 dB improvement in signal-to-noise over standard techniques, with an efficiency loss of less than 1.5 dB with respect to an ideal array. Our analysis also reveals that such antennas have a substantially wider operating bandwidth than traditional phased arrays, further expanding the range of potential applications.
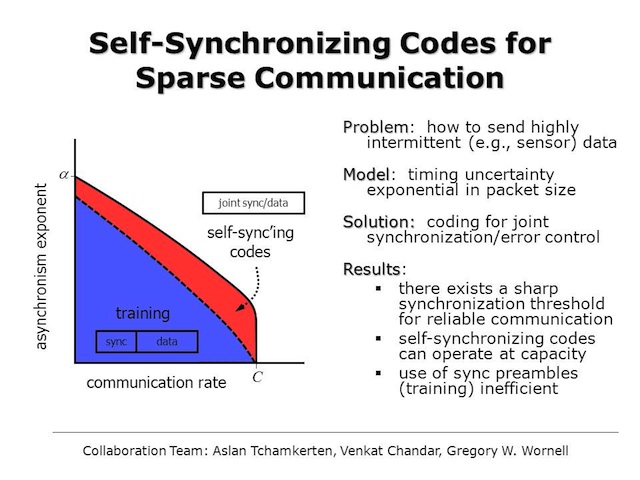
Self-Synchronizing Codes for Sparse Communication
Aslan Tchamkerten, Venkat Chandar, and Gregory W. Wornell
In traditional communication system architecture, the subsystem that encodes and decodes the bits to be communicated is designed and implemented separately from the subsystem that establishes a synchronized channel (e.g., by training). For example, typically a pseudonoise sequence is prepended to a packet of data to enable synchronization prior to decoding. However, in many emerging applications, such as in the realm of sensor networks, communication is inherently intermittent or bursty. We develop and analyze a model for such sparse communication scenarios, showing that there is a fundamental tradeoff between the highest rate at which communication is possible and the degree of sparseness. Such analysis reveals that there is sharp sparseness threshold beyond which reliable communication is fundamentally not possible. At the same time, away from this limit, we show that even when the channel is only used an exponentially small fraction of time, it is possible to communicate reliably at the traditional capacity of the channel. However, we further show that such communication is not possible using the traditional architecture. Rather, synchronization and communication must be implemented jointly, and we develop families of codes with suitable structure.
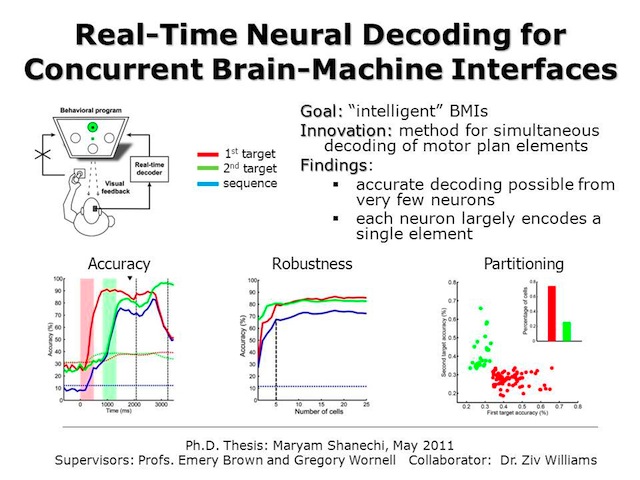
Real-Time Neural Decoding for Concurrent Brain-Machine Interfaces
Maryam M. Shanechi, Emery N. Brown, Ziv M. Williams, Gregory W. Wornell
Brain-machine interface (BMI) research has largely focused on the problem of restoring lost motor function in individuals. However, a more compelling aim of such research is the development of a truly “intelligent” BMI that can transcend original motor function by considering the higher-level goal of the motor activity and reformulating the motor plan accordingly. This would allow, for example, a task to be performed more quickly than possible by natural movement, or more safely or efficiently than originally conceived. Since a typical motor activity consists of a sequence of planned movements, such a BMI must be capable of analyzing the complete sequence before action. As such its feasibility hinges fundamentally on whether all elements of the motor plan can be decoded concurrently from working memory. In this work, we develop advanced neural decoding algorithms to demonstrate that such concurrent decoding is possible. In particular, we develop and implement a real-time BMI that accurately and simultaneously decodes in advance a sequence of planned movements from neural activity in the premotor cortex. In our experiments, monkeys were trained to add to working memory, in order, two distinct target locations on a screen, then move a cursor to each, in sequence. We find that the two elements of the motor plan, corresponding to the two targets, are encoded concurrently during the working memory period. Interestingly, our results also reveal: that the elements of the plan are encoded by largely disjoint subpopulations of neurons; that surprisingly small subpopulations are sufficient for reliable decoding of the motor plan; and that the subpopulation dedicated to the first target and their responses are largely unchanged when the second target is added to working memory. These results have significant implications for the architecture and design of future generations of BMIs with enhanced motor function capabilities.
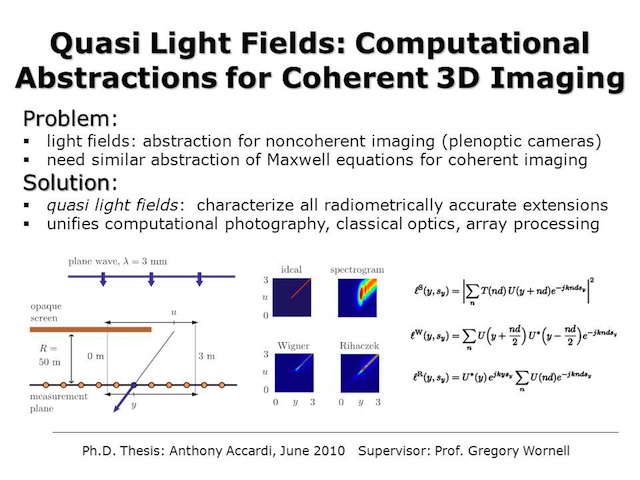
Quasi Light Fields: Computational Abstractions for Coherent 3D Imaging
Anthony Accardi and Gregory W. Wornell
A traditional image represents a view of a scene of interest that is optically consistent with what the human eye would perceive at a particular location and orientation relative to the scene. From this perceptual perspective, the field of photography has aimed to accurately reproduce such views. However, from an information perspective it is ultimately the 3D scene that is of direct interest, not the view itself. In such cases, the view corresponds to an intermediate representation of the scene, from which inferences can be made, including the locations and properties of sources and objects. In the computational photography community, where the focus is on noncoherent imaging at visible wavelengths, this perspectice has led to new view-independent “plenoptic” camera architectures. Such cameras are designed to capture the so-called light field as the intermediate representation, which constitutes a convenient computational abstraction derived from models based on geometric optics. For coherent imaging, scene reconstruction from field measurements can be straightforward for scenes that are particularly simple, such as those consisting of a small number of point sources. Indeed, in such scenarios the appropriate phased-array architectures for beamforming and more general array processing techniques follow immediately from the physics of electromagnetic propagation. For more complicated scenes, however, it is often impractical to directly exploit Maxwell’s equations. To address this issue, we develop and fully characterize all radiometrically accurate extensions of the light field to coherent imaging, which we refer to as quasi light fields by virtue of their close relationship to the quasi distributions that connect quantum and statistical mechanics. We further illustrate the potential of this higher-level computational abstraction using some simple but revealing examples. Ultimately, this research seeks to relate and unify diverse perspectives from computational photography, classical optics, and array processing.
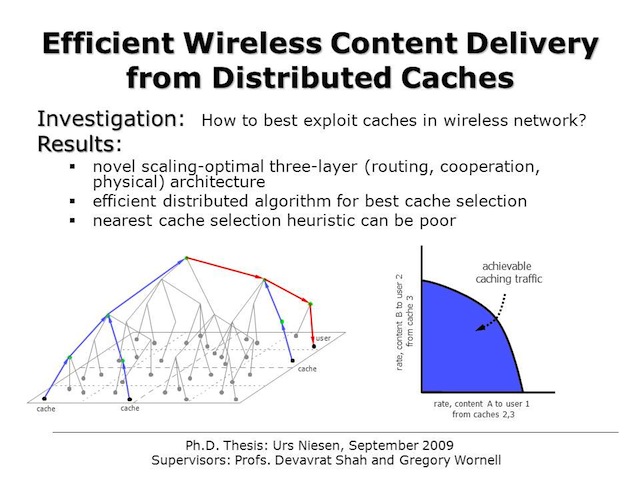
Efficient Wireless Content Delivery from Distributed Caches
Urs Niesen, Devavrat Shah, and Gregory W. Wornell
Users of wireless network services seek access to an ever growing volume of data on their mobile devices. Examples include a variety of video, audio, and image content, as well as a variety of other forms of data. For content that changes much less frequently than it is
requested, network operators increasingly rely on cache-based architectures to ease the burden of such demands on their networks. In particular, frequently requested content is stored in advance at several nodes in the network. We examine how such caches are best used in a large wireless network where each node in the network independently requests one or more items of content, each of which is cached at multiple locations. For this scenario, we develop a novel three-layer architecture whose supportable data rates for these requests scales scales optimally with the network size in the strong path-loss regime. In this architecture, the routing layer at the top treats the wireless network as a tree graph and routes pieces of an item of content from the caches to the destinations. In the middle, the cooperation layer provides the tree abstraction by appropriately distributing and concentrating traffic over the network. Finally, at the bottom, the physical layer implements the distribution and concentration, dealing with the effects of noise and interference. Conveniently, we show that the problem of optimally selecting which caches should serve the content to the user, and which proportions of the content each such cache should provide, can be solved efficiently by a distributed algorithm requiring access only to the routing layer abstraction of the network. Additionally, we establish that the commonly used heuristic of serving content to a user from the nearest cache can lead to particularly poor performance. Collectively, our results provide a variety of useful design principles of wireless network architects.
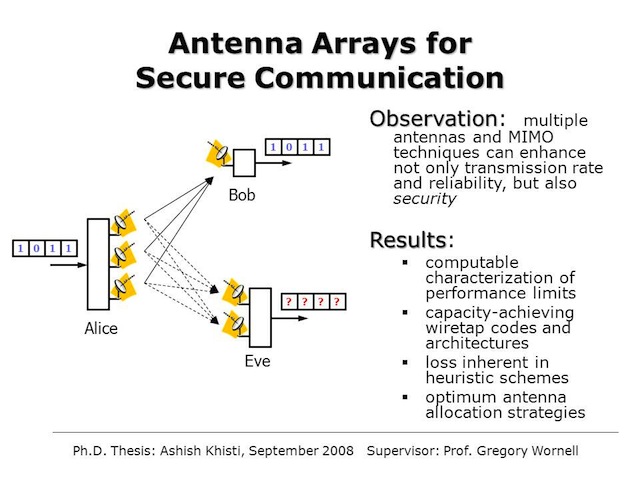
Antenna Arrays for Secure Communication
Ashish Khisti and Gregory W. Wornell
It is well understood that multiple-element antenna arrays, when combined with appropriate multi-input multi-output (MIMO) communication techniques, can greatly increase robustness and throughput in wireless communication systems. As a result, there has been extensive deployment of such technology in recent years. However, such technology has an equally important role to play in increasing security in wireless communication. In this work, we investigate a wireless scenario in which there is a sender, an intended receiver, and a computationally-unbounded eavesdropper, each of which has its own antenna array. For such systems, we develop a computable expression for the secrecy capacity, i.e., the highest rate at which the sender can communicate to the legitimate receiver without leaking information to the eavesdropper, as a function of the numbers of antennas involved and the particular channel realizations. As part of such analysis, we design “MIMO wiretap codes” for approaching such fundamental limits. Interestingly, such codes can be significantly better than seemingly natural “masked MIMO” designs that send information along directions in which there is gain to the intended receiverand synthetic noise along directions in which there is not. Our analysis also leads to some useful rules of thumb for system design: 1) to optimally thwart an attacker, sender and legitimate receiver should divide their available antenna elements between them in the ratio of 2:1; and 2) to prevent secure communication, the eavesdropper needs 3 times as many antenna elements as sender and intended receiver have combined.
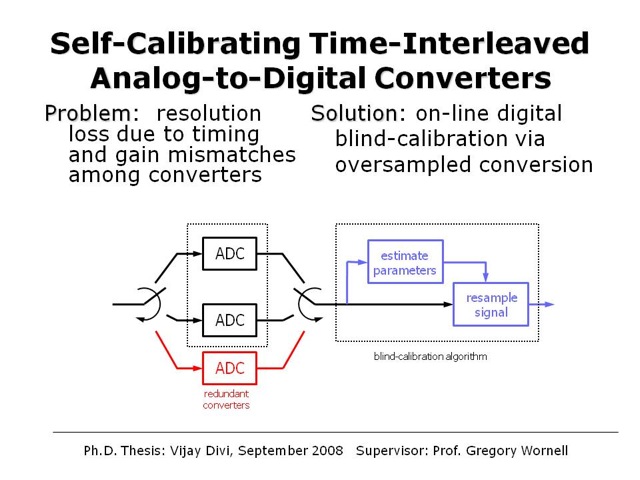
Self-Calibrating Time-Interleaved Analog-to-Digital Converters
Vijay Divi and Gregory W. Wornell
One popular method for achieving very high-speed analog-to-digital conversion is to use several slower speed converters in a round-robin fashion. However, in practice there are gain differences among the constituent converters due to component variation, and the overall sampling is nonuniform due to disparities in converter output path lengths on-chip. As a result, the effective converter resolution can easily be several bits per sample less than that of the constituent converters. A traditional approach to addressing this problem has been to calibrate the converter by feeding it a training signal and using the output to adjust its parameters. However, this requires taking the converter off-line periodically, which is unacceptable in many applications. In this work, we show, somewhat counterintuitively, that by using more such imperfect converters so that the input is oversampled relative to its Nyquist rate, it is possible to implement accurate calibration on-line in blind manner, i.e., without requiring knowledge of converter input. In particular, we design iterative algorithms for learning the converter parameters on-the-fly, which are subsequently used to perform correction in either a feedback mode, whereby the converter parameters are directly adjusted, or in a feedforward mode, whereby the converter output is digitally resampled. Such blind calibration is an example of a growing trend toward digitally-enhanced analog circuit designs.
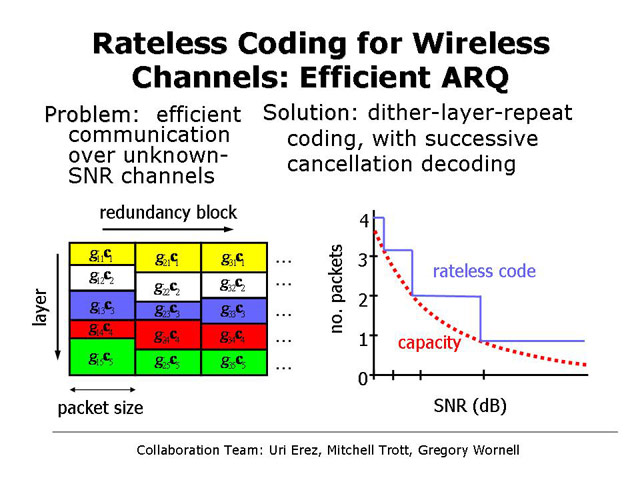
Rateless Coding for Wireless Channels: Efficient ARQ
Uri Erez, Mitchell D. Trott, and Gregory W. Wornell
In wireless networks, there is much variation in the signal-to-noise ratio (SNR) on individual links. As a result, it is common for communication to be preceded by a training phase, whereby the receiver estimates the channel and conveys this channel state information (CSI) back to the transmitter. However, in highly dynamic networks typical of mobile applications, there is often a serious mismatch between the actual and last-measured states of the channel during transmission, which ends up overwhelming the automatic repeat-request (ARQ) mechanism in the network and dramatically reducing throughput relative to what capacity analysis would promise. In this work, we show that a suitable cross-layer architecture can avoid this problem. In particular, we develop a joint physical-layer/link-layer design in the form of a rateless code. In this design, no CSI is required at the transmitter. Rather, a message is encoded into a sequence of incremental redundancy blocks. The receiver attempts decoding after receiving each such block, and when successful informs the transmitter to terminate transmission. We show that a construction based on simple linear combinations of submessages can: i) achieve the (a priori unknown) capacity of the channel; and ii) be decoded with extremely low complexity when the generator matrix is appropriately chosen. The resulting code can be interpreted as a maximally efficient hybrid ARQ scheme.
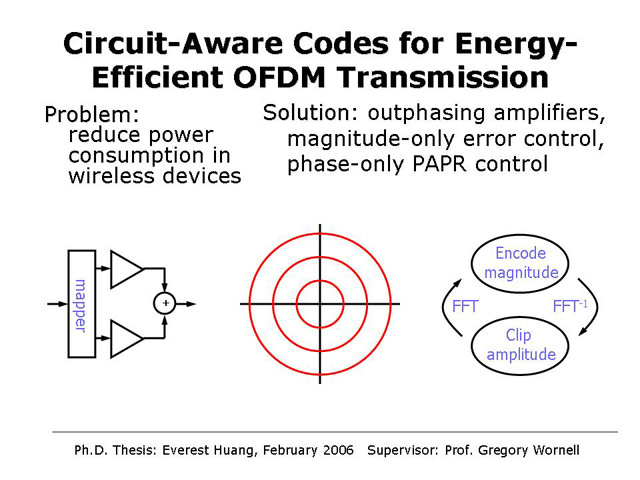
Circuit-Aware Codes for Energy-Efficient OFDM Transmission
Everest Huang and Gregory W. Wornell
Orthogonal frequency-division multiplexing (OFDM) is an increasingly attractive transmission format for wireless and wireline communication standards. However, OFDM waveforms traditionally suffer from high peak-to-average power (PAPR) characteristics, so that when used with typical linear RF amplifiers, power consumption is excessive. This work explores the joint design of the transmission waveforms and RF amplifiers, i.e., the design of circuit-aware codes, and code-aware circuits. We show that in low-power applications, by using such an approach it is possible to reduce power consumption by a factor of more than three, which in wireless applications dramatically extends the operating time of mobile devices. The key ingredients of our system are the combination of novel outphasing RF amplifiers—which are are highly power efficient—and magnitude-only information encoding—which is rate-efficient in the low SNR regime of interest. In this system, the transmission phase is adjusted via a suitably designed iterative algorithm to minimize PAPR.
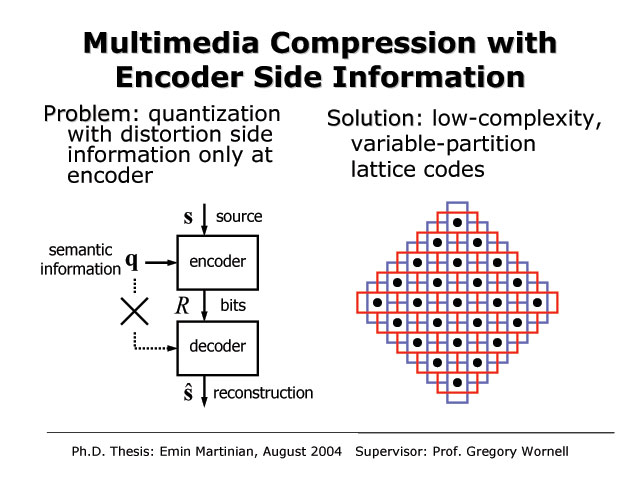
Multimedia Compression with Encoder Side Information
Emin Martinian and Gregory W. Wornell
In many applications, there is a need for digital representations of various kinds of content. Such content includes, for example, video, audio, imagery, as well as various kinds of sensor data. To develop compact representations, one needs to take into account the semantics of the content. In particular, the goal is not to enable an exact
reconstruction of the content, but rather one that is semantically indistinguishable from original for the applications of interest. In Shannon’s formulation of the problem, the semantics are captured through a distortion measure. When such semantic information is shared between encoder and decoder, the fundamental rate-distortion tradeoffs are well understood. This work explores the corresponding tradeoffs when such semantic information is not universally available. We show, for example, that when only the decoder has access to the full semantics, it provides no benefit and may as well be ignored. By contrast, when only the encoder has access to the full semantics, in many cases that is sufficient to do as well as if the decoder had it too. Moreover, we show that systems in which such semantic information is measured at the encoder and shared with the decoder through a side channel — which is the basis of many perceptual coding systems, for example — can be particularly inefficient. As an efficient alternative, we introduce low-complexity lattice codes in which there is a fixed codebook but a variable partition to exploit encoder-only side information.
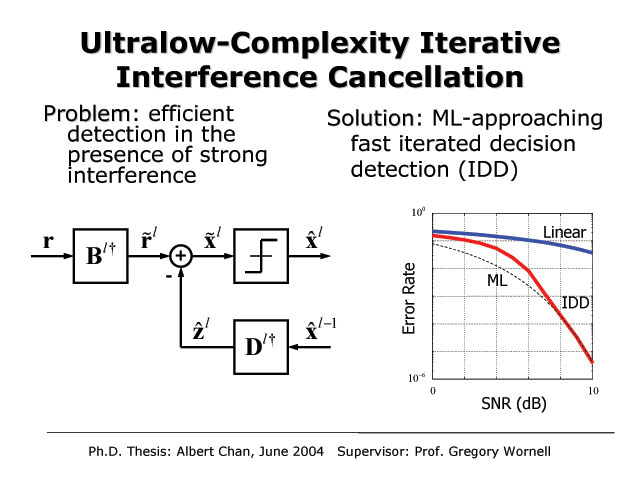
Ultralow-Complexity Iterative Interference Cancellation
Albert Chan and Gregory W. Wornell
In many communication applications, the dominant impairment is interference. This is especially true of wireless environments. There is typically self-interference due to multipath propagation. When system bandwidths are large enough, this takes the form of intersymbol interference. However, there is also interference from other users in the next work, as well as various forms of extra-network interference. The degree to which such interference can be mitigated through signal processing within the network strongly affects the overall capacity. Thus interference-cancellation algorithms are of considerable interest. However, traditional low-complexity linear interference cancellation techniques cannot exploit enough of the structure in the interference to be effective, while maximum-likelihood (ML) interference cancellation are the most effective, but have exponential complexity. We show that in fact, the performance of ML cancellation can be approached at high SNR with a complexity that is negligibly higher than the linear techniques. In particular, we develop an efficient convergent iterative algorithm structure that alternates between generating increasingly reliable symbol decisions and increasingly reliable interference estimates. Combining such decoding structures with a precoding technique at the encoder we refer to as mode-interleaving extends their effectiveness to a particularly broad range of channels.
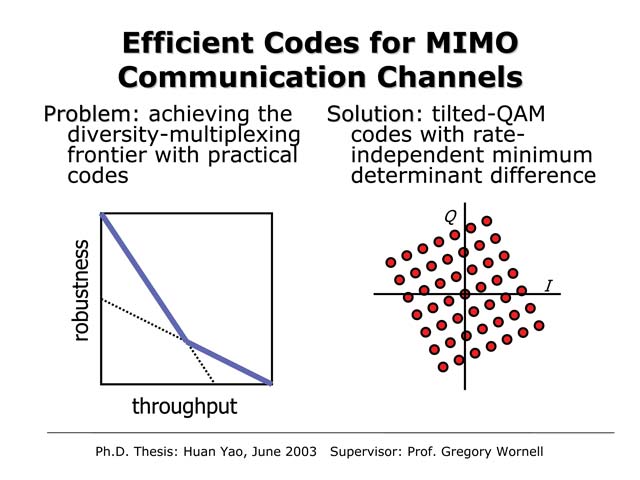
Efficient Codes for MIMO Communication Channels
Huan Yao and Gregory W. Wornell
As multiple-element antenna arrays become an increasingly important ingredient of high-speed wireless networks, there is a corresponding need for physical-layer system designs that create fat, reliable bit pipes from such channels. Recently, the fundamental tradeoff between throughput and robustness has been quantified in the form of what is referred to as the diversity-multiplexing frontier. While it was understood the sufficiently long and random codes code approach arbitrary points on this frontier, it was not known whether all such points are achievable with practical codes. We show that suitable designed titled-QAM codes, in which a multidimensional constellation is subjected to a unitary transformation, can in fact achieve the full frontier. Moreover, they achieve this frontier even for the shortest code lengths where random codes cannot. A key property of this new family of codes has the property that their minimum determinant difference is independent of the constellation size (and hence transmission rate). Such codes can be used in conjunction with other traditional error-correction codes and appropriately designed iterative decoding, and are considerably more efficient than the popular orthogonal space-time block codes at higher spectral efficiencies.
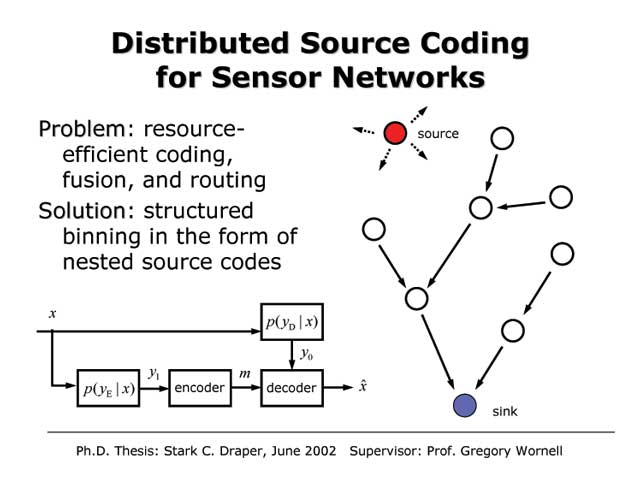
Efficient Quantization for Sensor Networks
Stark C. Draper and Gregory W. Wornell
In many peer-to-peer sensor network architectures, the signal measurements acquired at nodes are quantized, and the associated bit representations are propagated through the network to data fusion nodes where inference is performed. From this perspective, the quantizer design problem can be viewed as one of coding for estimation with communication constraints. A naive approach would have each node design its quantization without regard for the network structure. However, a substantially more resource efficient network results from the quantizer taking into account that the intermediate nodes propagating these bit representations are receiving their own measurements as well as bit representations from other nodes. From an information-theoretic perspective, this these intermediate nodes have so-called side information that can be exploited in the code design. We develop powerful greedy coding algorithms based on this principle, and show how they achieve or approach fundamental limits in prototype topologies. From an architectural perspective, the new algorithm represents the design of a network-aware application layer for this problem, which our results establish is substantially more resource-efficient than a traditional layered architecture.
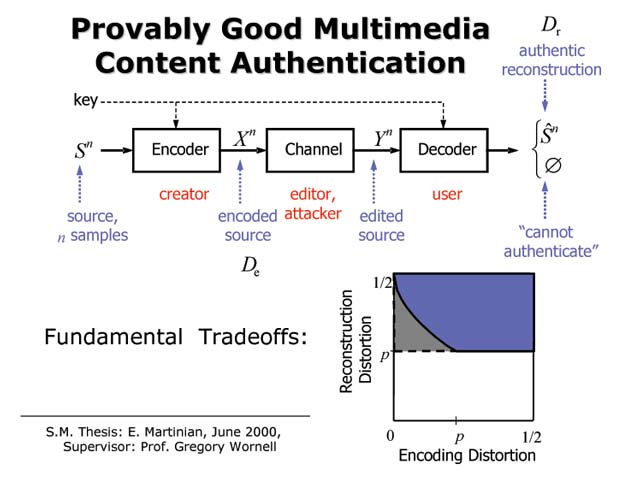
Multimedia Content Authentication
Emin Martinian and Gregory W. Wornell
In today’s world, we find ourselves both impressed by and uncomfortable with the ease with which one can use digital tools to manipulate audio, video, imagery, and other kinds of multimedia content. One might reasonably ask whether it is possible in such a world to make, for example, a photograph that is truly trustworthy in some precise sense. In this work, examine this question, develop a meaningful mathematical model for the problem, and analyze the associated fundamental performance limits of authentications systems that provide a security guarantee. We further develop the structure of systems that approach these limits, and see that the resulting coding strategies can be viewed as rather powerful generalizations of traditional digital signatures. Moreover, we show that such systems can be built from familiar ingredients put together in some rather new ways. More generally, our investigation reveals that such multimedia security problems are inherently highly interdisciplinary, and that practical solutions require jointly exploiting concepts from information theory, coding and communication theory, signal processing and systems theory, and cryptography and complexity theory.

Cooperative Diversity for Wireless Networks
J. Nicholas Laneman and Gregory, W. Wornell
In a typical wireless network, users exploit their available power and bandwidth resources to communicate their messages to their target destinations as efficiently as possible, and ignore or avoid the messages of other transmitting users. However, we show this selfish strategy is, in fact, not in the collective interest of the group: through cooperation each individual user can experience better performance. In particular, if each user devotes some of its resources to relaying the transmissions it hears from other users as well as to sending its own message, each message is received with higher reliability because it experiences multiple propagation paths. Indeed, with this protocol, the group of cooperating users are forming a “virtual” antenna array, from which there is a substantial spatial diversity benefit. We show that, in fact, very simple relaying schemes yield full spatial diversity: each user’s message experiences performance as if it were sent from a physical antenna array of the same size. These lead naturally to novel and efficient distributed space-time codes for networks, which are equally applicable to cellular and ad-hoc architectures. From an architectural perspective, such protocols require only a relatively small violation of the traditional abstraction rules that impose a separation of the physical, link, and network layers.
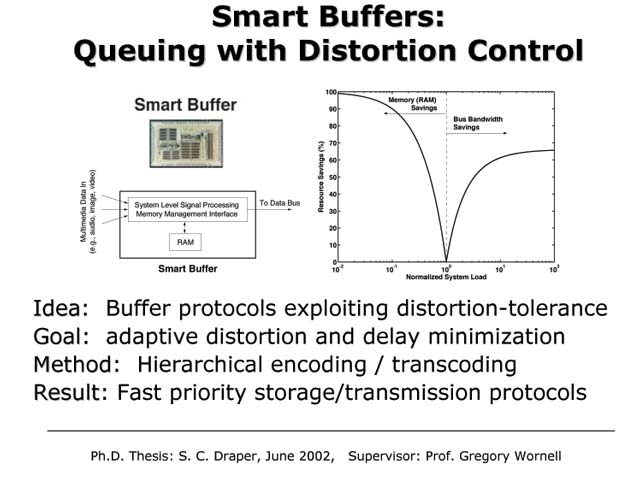
Smart Buffers for Multimedia Content
Stark C. Draper, Mitchell D. Trott, and Gregory W. Wornell
Buffers find application in a wide range of contexts, from digital hardware and software systems to broadband packet-switched networks like the Internet. Traditionally, such buffers are designed without regard for the characteristics of the content they will hold. For example, with a simple first-in/first-out (FIFO) buffer, if during some interval of time the number of bits that needs to be stored exceeds the memory resources, some are simply dropped. When those bits represent some multimedia content of interest, the dropped bits correspond to a loss of fidelity. In this work, we examine the design of a smart buffer that takes into account how each bit contributes to the fidelity of the content stored in memory, and develop a buffering algorithm that optimizes end-to-end fidelity. In particular, we develop a greedy algorithm is sample-path optimal: regardless of the pattern of arrivals to and departures from memory, no other algorithm, greedy or not, can achieve better performance. This algorithm ensures that most-significant bits are both stored in memory first and depart memory first, with the resource allocation managed by an easily implemented waterpouring strategy. The smart buffer achieves a given end-to-end fidelity target with considerably less storage and communication resources than traditional designs. From a system or network architecture perspective, the resulting design shows how increasing lower layer awareness of the application layer in relatively simple ways can substantially improve resource efficiency.
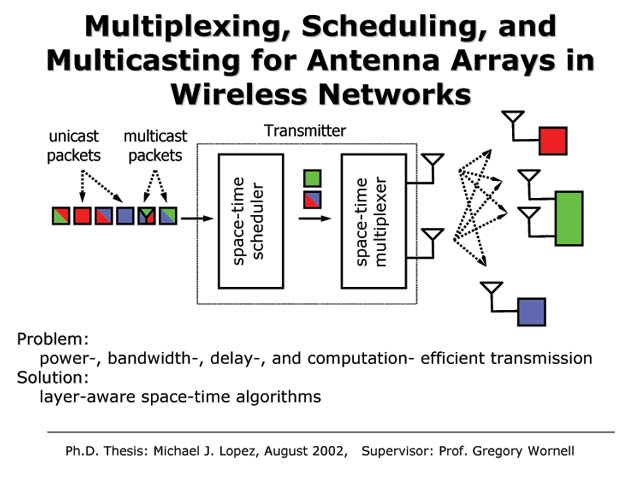
Scheduling for Multiple Antenna Wireless Transmission
Michael J. Lopez and Gregory W. Wornell
It is well known that the use of multiple antennas can enhance the capacity of wireless links delivering messages to geographically dispersed receivers. Moreover, in applications where the channel state information is available at the transmitter, efficient precoding strategies (based on information embedding concepts) exist for multiplexing the different messages to be delivered to different users. In particular, this precoding performs an interference pre-cancellation operation that ensures the different target receivers can ignore interference effects when decoding their messages. However, in typical networks, the collection of messages to be transmitted can be quite large, and a scheduler selects a subset to be multiplexed in any particular transmission interval. When the scheduler and multiplexor operate independently, the scheduler complexity is very low, but the multiplexor can require substantial complexity. We show that by having the scheduler make efficient use of a latency window and take into account the implications of its decisions for multiplexing, the overall system can be much more efficient. In particular, the complexity of multiplexing is significantly reduced while requiring only a small increase in the complexity of scheduling. In addition to highlighting the role of delay as a resource, this work is another compelling illustration of how a modest amount of lower-layer awareness at the networking layers can substantially improve overall resource efficiency from a network architecture perspective.
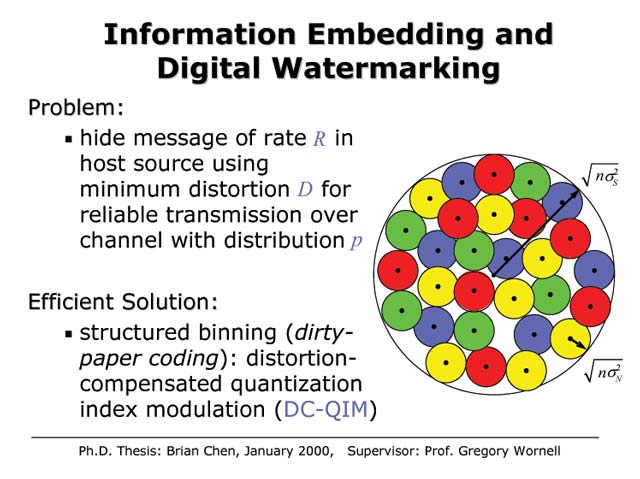
Information Embedding and Digital Watermarking
Brian Chen and Gregory W. Wornell
In a variety of emerging applications, there is a need to hide a sequence of bits in some host signal like a photograph or a radio transmission. Applications range from digital rights management and copyright notification and enforcement, to backwards-compatible upgrades to existing communication infrastructure, broadcasting, and covert communication. In such problems, there is an inherent tradeoff between the number of bits embedded, the robustness with which they are embedded, and the distortion the embedding incurs on the host signal. In this research, we show this problem is equivalent to an information theoretic problem of channel coding with side information at the encoder, and use the equivalence to characterize the tradeoff and develop the associated fundamental limits. We further introduce a practical and efficient encoding scheme we refer to as quantization index modulation (QIM), and a distortion-compensation techniques (DC-QIM), for achieving the fundamental limits. The key to the effectiveness of QIM is the way it ensures that the host signal is not a source of interference at the decoder. Indeed, data hiding systems based on DC-QIM are orders of magnitude more efficient than the more familiar data hiding systems based on spread-spectrum methods, in which there is host signal interference. This research underscores the importance of careful problem modeling to effective algorithm design.

The “Dirty Paper” Codec Project: A Real-Time, Capacity-Approaching Information Embedding System
Laboratory Partnership with Chinook Communications
The foundations of information embedding were laid more than twenty years ago with early information-theoretic work on the problem of channel coding with side information at the encoder. One of those early papers was Costa’s whimsically titled “Writing on Dirty Paper”. In recent years, four key advances have made possible the development of practical information embedding systems. First is the recognition that the information embedding problem can be cast as a problem of “writing on dirty paper”. Second is the development of practical code constructions in the form of distortion-compensated quantization index modulation (DC-QIM). Third is the development of capacity-approaching turbo codes with very low complexity iterative decoding algorithms. And fourth is the maturation of VLSI technology and the associated development tools. In this project, all four of these advances are exploited together in the design of the world’s first real-time, capacity-approaching information embedding system: the “dirty paper” coder/decoder (codec). This system transparently embeds a bitstream at 6 Mb/s into an arbitrary analog NTSC television signal so that it can be reliably transmitted through, for example, any FCC-compliant cable network. Such systems could be used to add roughly 300Mb/s additional downstream capacity to cable infrastructure without requiring plant upgrades or affecting existing services. The system operates within a couple of dB of capacity, and the reference design is complete with analog front end, 400k gate FPGA codec, full DSP-based software equalization, and an embedded linux controller. Other emerging applications of this technology include multi-antenna downlink transmission in wireless systems.