Research
Emerging fields such as artificial intelligence (AI) and robotics rely on computationally complex algorithms to achieve high accuracy that enable new applications and discoveries. While much of the compute for these applications currently happens in the cloud (i.e., data center), processing locally on the device (e.g., smartphone or robot) is often desirable due to latency, security/privacy, and communication bandwidth concerns. However, local processing on an embedded device is challenging as the energy is limited by its battery capacity.
The Energy-Efficient Multimedia Systems Group aims to drastically reduce the energy consumption of these computationally complex algorithms for embedded applications while delivering real-time performance. Our group develops efficient computing methods that cross traditional research boundaries between algorithms and hardware (including circuits, architectures, and systems). Our approaches have been demonstrated on a broad range of applications including deep neural networks, autonomous navigation for robotics, and video compression. Our contributions have enabled orders of magnitude improvement in energy-efficiency and speed so that we can carry, wear, drive and fly the compute for these complex algorithms.
Short overview of our research can be found at [ Video ].
Current research topics
- Energy-Efficient Deep Learning, Computer Vision, and Autonomous Navigation
- Mobile Health Monitoring
- Accelerating Super Resolution
- Next-Generation Video Coding
Example Research Projects


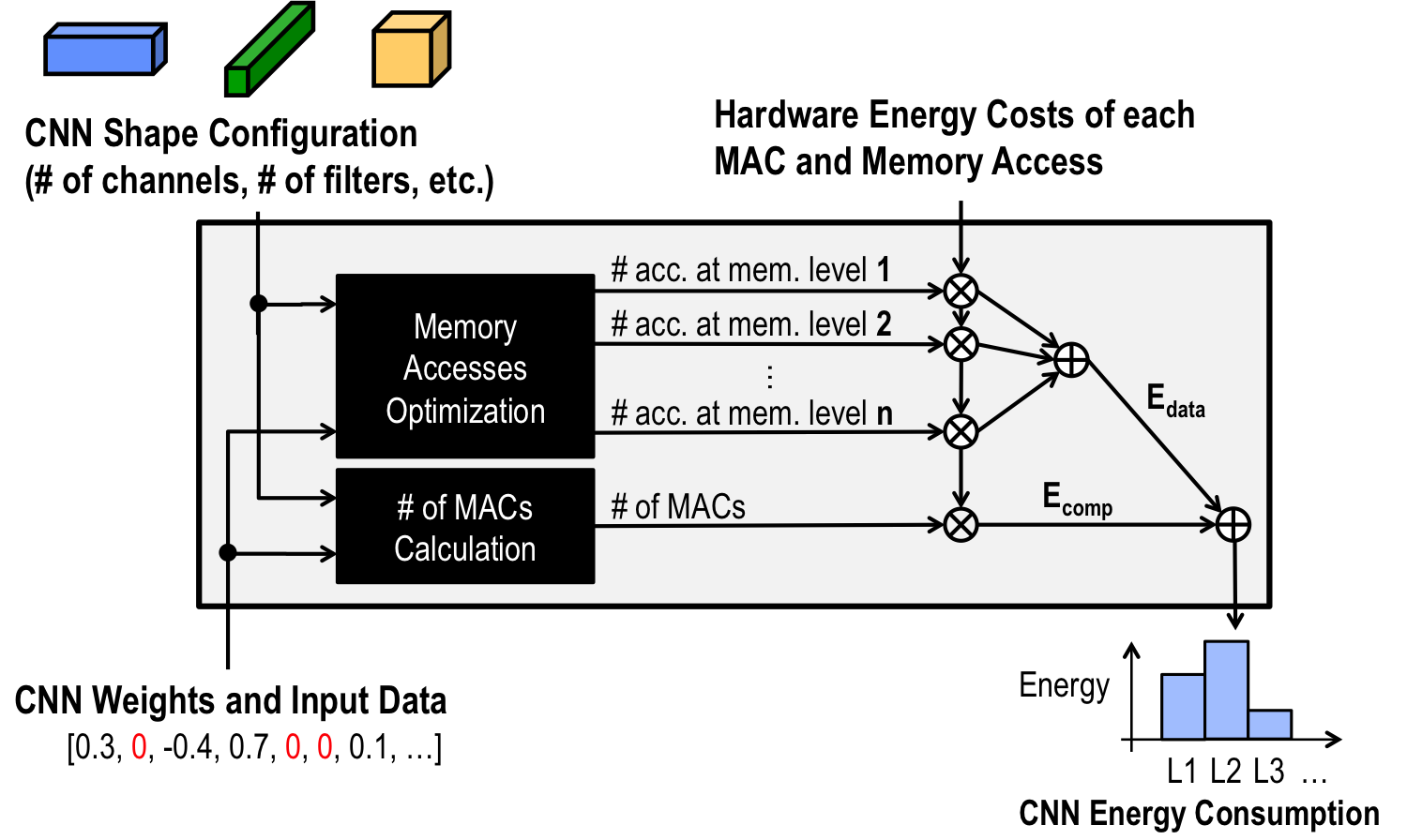
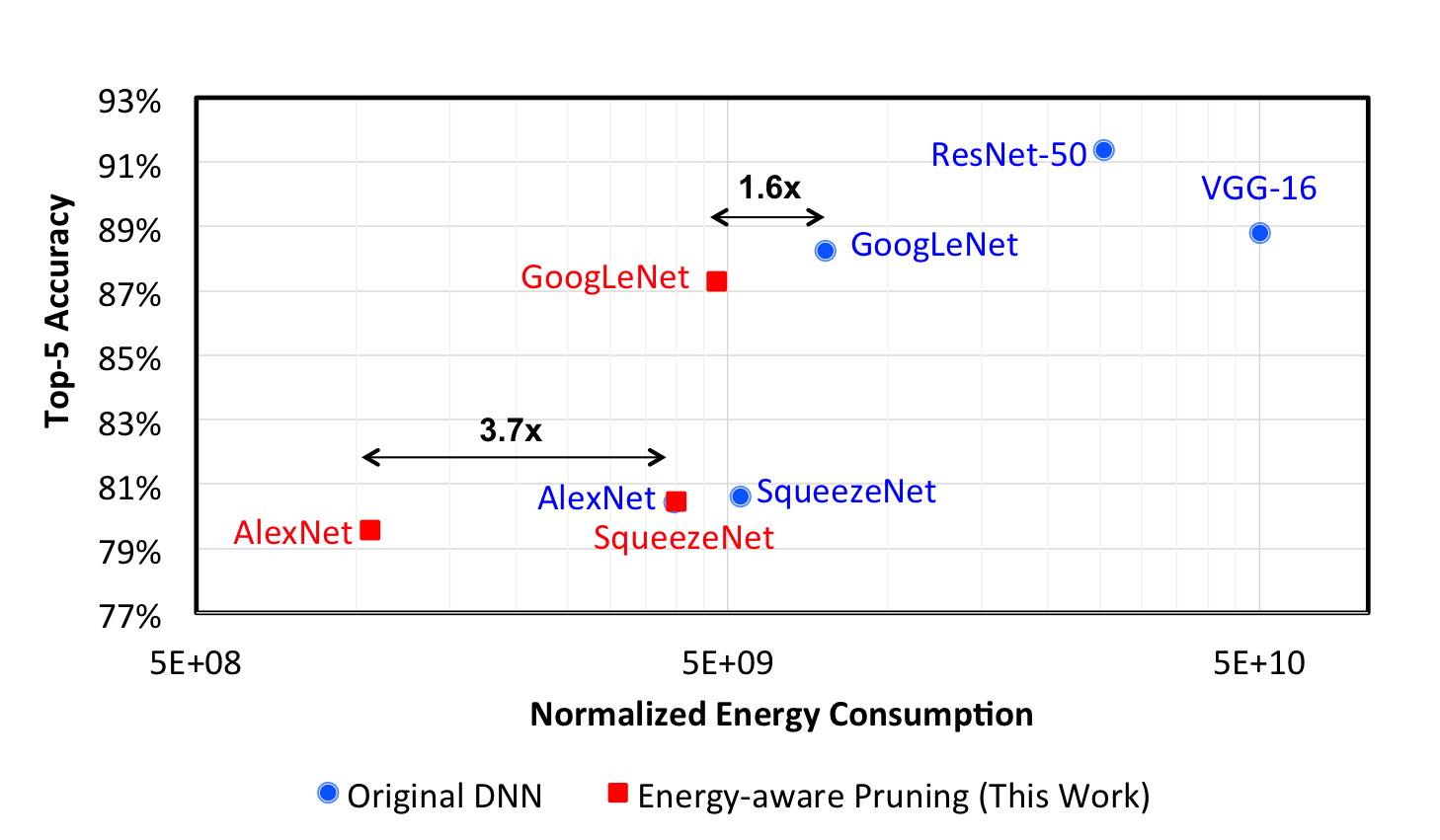
Efficient Processing of Deep Neural Networks
Deep neural networks (DNNs), aka deep learning, deliver state-of-the-art accuracy on a wide range of AI tasks (e.g., computer vision, robotics) at the cost of significant amounts of compute. Compared to other forms of signal processing such as video compression, DNNs consume two to three orders of magnitude more energy. If we want deep learning to be as pervasive as video compression on embedded devices, we must close this energy gap.
Efficient and Flexible Hardware Architectures
(In collaboration with Joel Emer. Subgroup website: Emze): One important property of the DNN workload is that there are many opportunities for data reuse (i.e., the same data is used for many operations). We developed an architecture called Eyeriss, that combines a specialized memory subsystem with an efficient dataflow, which dictates the processing order and mapping of the workload onto the memory hierarchy, to exploit data reuse at the low-cost memories.
Our research identified that dataflows are a distinguishing characteristic of deep learning accelerators and devised a taxonomy (e.g., * – stationary) to classify the large design space in terms of dataflows to help researchers reason about this space [ISCA2016]. Eyeriss introduced the concept of a row-stationary dataflow that accounts for the data movement of all data types to reduce the overall data movement; in addition, it can exploit all forms of available data reuse (i.e., convolutional, filter, image) [ISCA2016]. Our work on efficient dataflows was selected as an IEEE MICRO Top Pick [MICROTopPicks2017]. Eyeriss is scalable, flexible and able to process much larger networks than can be stored directly on the chip; it achieves an order of magnitude higher energy-efficiency than a mobile GPU [ISSCC2016].
Given the rapid pace of deep learning research, it is critical to have flexible hardware that can efficiently support a wide range of workloads. For instance, recent DNN workloads reduce the available data reuse in certain dimensions (e.g., depth-wise layers); therefore, flexible mapping is required so that reuse can be exploited in any dimension to maximize efficiency and core utilization. Accordingly, the second version of Eyeriss focused on a novel scalable on-chip network organization that is both cheap and flexible enough to provide high throughput across a range of important DNN workloads [JETCAS2019]. In addition, Eyeriss v2 adapts gracefully to changes in sparsity and is unique in efficiently handling cases where the data is either dense or sparse. Due to these extensions, Eyeriss v2 achieves an order of magnitude improvement in energy-efficiency and speed over Eyeriss v1. We also introduced an analysis methodology called Eyexam that provides a systematic way of understanding the performance limits for DNN processors as a function of specific characteristics of the DNN workloads and accelerator design; it applies these characteristics as sequential steps to increasingly tighten the bound on the performance limits [arXiv].
As deep learning is a fast-moving area of research, we have put together various tutorial and overview material to help students, researchers, and practitioners navigate the space. This includes a tutorial paper on Efficient Processing of Deep Neural Networks for the Proceedings of the IEEE [PIEEE2017] and tutorials at various conferences [ Link ]. We received the 2017 CICC Outstanding Invited Paper Award for our overview paper on hardware for machine learning [CICC2017]. Finally, we have released energy modeling tools for DNN workloads [Asilomar2017] and accelerators [ICCAD2019, ISPASS2020].
Efficient Algorithms: We identified that the number of weights and operations are not indicative of energy consumption and latency, and designing networks based on these indirect metrics can result in slower and more energy costly designs. We developed several algorithms that can incorporate direct metrics, such as energy consumption and latency directly into the network design, to generate workloads that can be efficiently processed in hardware for an improved accuracy versus latency/energy trade-off. While previous state-of-the-art pruning approaches removed weights of the DNN based on their magnitude (i.e., removed small weights), we proposed a method called energy-aware pruning that could remove weights based on their estimated energy consumption [CVPR2017]. In collaboration with Google’s Mobile Vision Team, we developed NetAdapt, which extends this approach to include both latency and energy, and automates the process so that it can be easily applied to a wide range of embedded platforms [ECCV2018]. While most research on efficient networks focuses on image classification, we also demonstrated our approach on the more challenging task of depth estimation; FastDepth achieved over an order of magnitude speedup while achieving near state-of-the-art accuracy [ICRA2019]. Finally, we observe that designing DNNs for processing-in-memory accelerators may differ from the common approaches for digital accelerators [IEDM2019].
Related Publications: ISSCC2016, ISCA2016, JSSC2016, CVPR2017, CICC2017, ISCAS2017, PIEEE2017, MICROTopPicks2017, Asilomar2017, SysML2018, ECCV2018, JETCAS2019, ICCAD2019, IEDM2019, ISPASS2020
DNN energy estimation tool website.
Please visit the project website for more info.
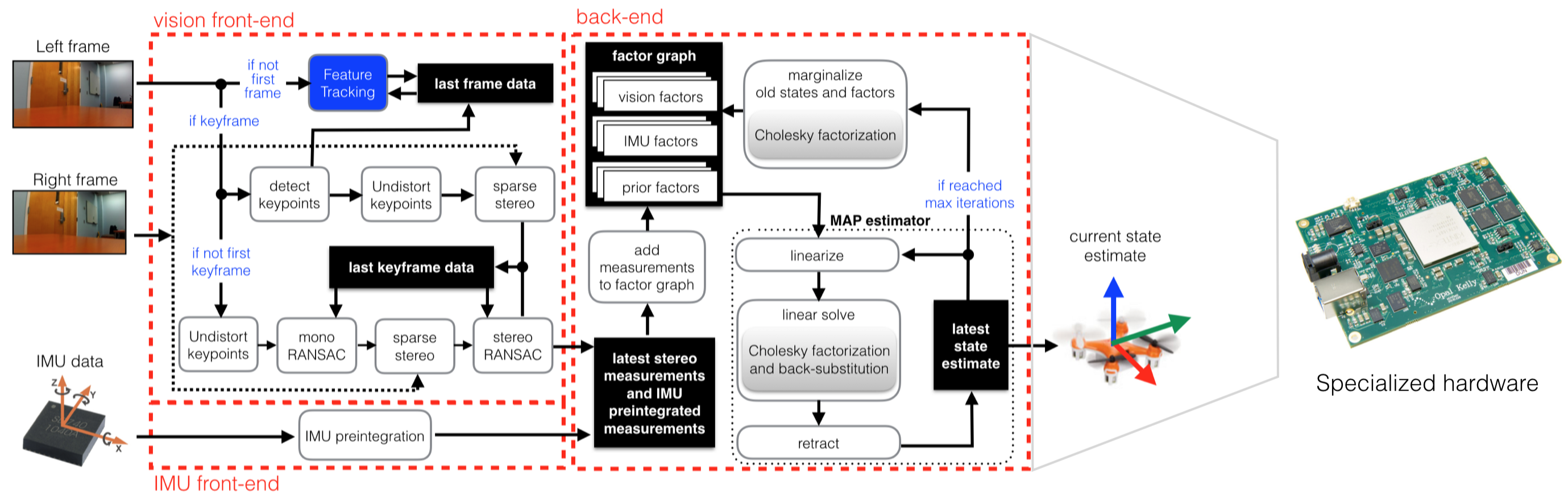
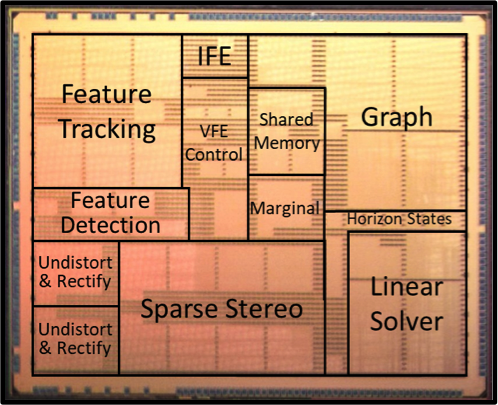
Autonomous Navigation for Low Energy Robotics
(In collaboration with Sertac Karaman. Subgroup website: LEAN)
A broad range of next-generation applications will be enabled by low-energy, miniature mobile robotics including insect-size flapping-wing robots that can help with search and rescue, chip-size satellites that can explore nearby stars, and blimps that can stay in the air for years to provide communication services in remote locations. While the low-energy, miniature actuation, and sensing systems have already been developed in many of these cases, the processors currently use to run the algorithms for autonomous navigation are still energy-hungry. Our research aims to address this challenge by bridging the field of robotics and hardware design [ Video ].
Localization
The first key step in autonomous navigation is for the robot to determine its location. A popular approach for robot localization is visual-inertial odometry, which is also widely used for augmented/virtual reality (AR/VR). We co-designed an algorithm and hardware that performs localization by fusing visual information and inertial measurements using factor graph optimization, which handles non-linearity in sensing and motion, to achieve state-of-the-art accuracy [RSS2017]. We developed compact representations based on the different properties of data (e.g., structured/unstructured, sparse/dense) and the sensitivity of the algorithm to the data at each stage of the pipeline; this allowed the entire system to be fully integrated on-chip, eliminating costly off-chip data movement and reducing system integration cost. Finally, we parameterized the algorithm so that we can adapt the processing based on the difficulty of the dynamically changing environment to further reduce energy consumption. The Navion chip is the first chip able to deliver real-time state-of-the-art localization at 2 mW [JSSC2019], which is several orders of magnitude more efficient than prior solutions and sufficiently low power to be mounted on a nano-robot or integrated into an AR headset. We received the 2018 Symposium on VLSI Circuits Best Student Paper Award for Navion [VLSI2018], which was also presented at Hot Chips [ Video ].
Exploration
Robot exploration is used for applications such as search and rescue. A key bottleneck to exploration speed is the complexity of computing Shannon’s mutual information (MI), which determines the next location that the robot should explore to reduce the uncertainty of an unknown environment; due to the complexity of MI, roboticists have had to use heuristic-based approaches that do not have provable guarantees. We co-designed an algorithm and hardware to accelerate the computation of MI. First, we propose a new algorithm called Fast computation of Shannon’s Mutual Information (FSMI), which reorders the core operations to eliminate large summations resulting in orders of magnitude speed up [ICRA2019, IJRR2020]. Next, we designed a specialized memory subsystem that reduces read conflicts between parallel cores by optimizing memory mapping and arbitration; as a result, its throughput reaches 94% of the theoretical limit (i.e., unlimited memory bandwidth) [RSS2019] allowing us to compute MI for the entire map in near real-time for the first time. Finally, we directly compute MI on a compressed 3D map for an 8x speed up [IJRR2020], which enables the use of MI for flight exploration for the first time.
Related Publications: RSS2017, VLSI2018, HotChips2018, JSSC2019, ICRA2019, ICRA2019, RSS2019, ICRA2020, ICRA2020, IJRR2020
Please visit the project website for more info.
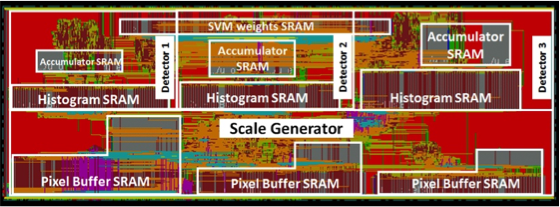

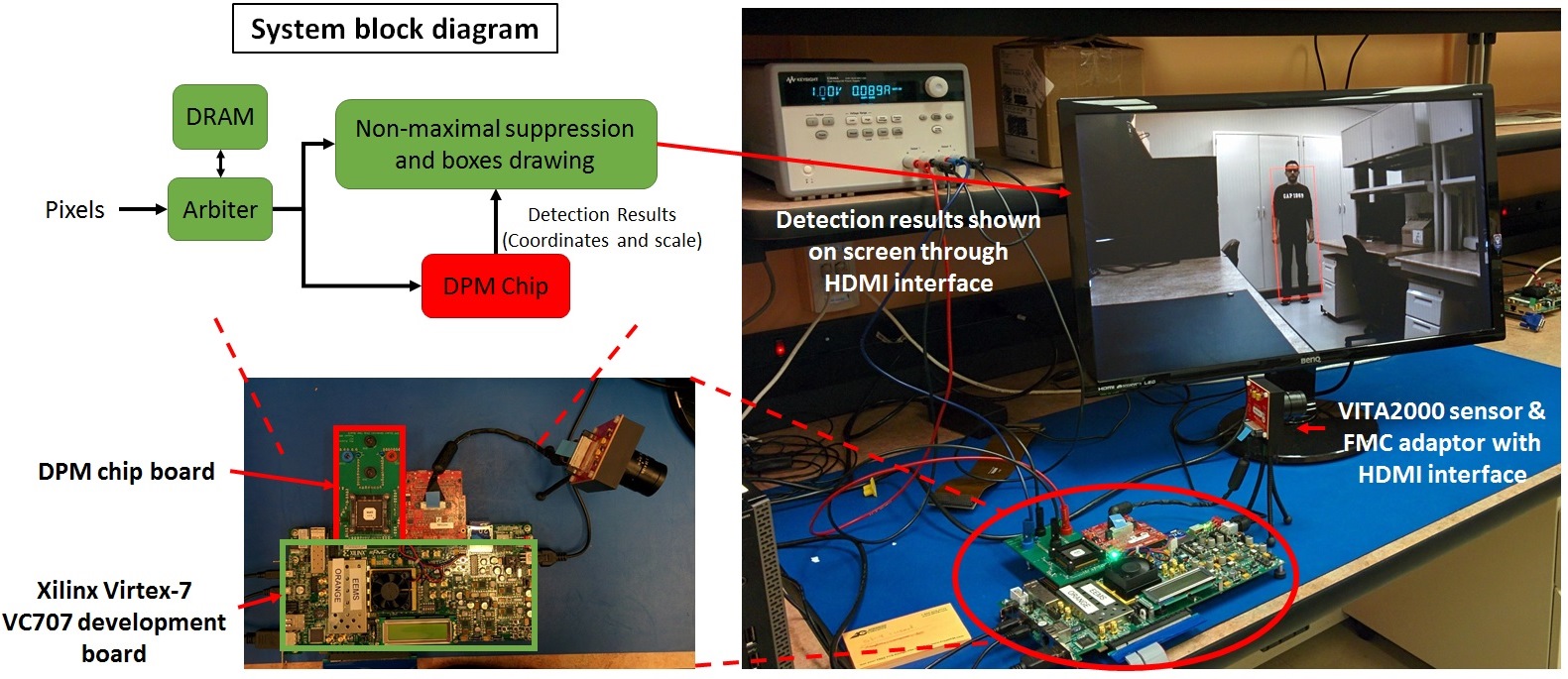
Towards Ubiquitous Embedded Vision
We would like to reduce the energy consumption substantially such that all cameras can be made “smart” and output meaningful information with little need for human intervention. As an intermediate benchmark, we would like to make understanding pixels as energy-efficient as compressing pixels, so that computer vision can be as ubiquitous as video compression, which is present in most cameras today. This is challenging, as computer vision often requires that the data be transformed into a much higher dimensional space than video compression, which results in more computation and data movement. For example, object detection, used in applications such as Advanced Driver Assistant Systems (ADAS), autonomous control in Unmanned Aerial Vehicles (UAV), mobile robot vision, video surveillance, and portable devices, requires an additional dimension of image scaling to detect objects of different sizes, which increases the number of pixels that must be processed.
In this project, we use joint algorithm and hardware design to reduce computational complexity by exploiting data statistics. We developed object detection algorithms that enforce sparsity in both the feature extraction from the image as well as the weights in the classifier. In addition, when detecting deformable objects using multiple classifiers to identify both the root and the different parts of an object, we only perform the parts classification on the high scoring roots. We then design hardware that exploits these various forms of sparsity for energy-efficiency, which reduces the energy consumption by 5x, enabling object detection to be as energy-efficient as video compression at < 1nJ/pixel. This is an important step towards achieving continuous mobile vision, which benefits applications such as wearable vision for the blind.
Related Publications: SiPS2014, JSPS2015, VLSI2016, JSSC2017, ISCAS2017

Low Power Time-of-Flight Depth Estimation
Depth estimation is critical for many applications from robotics to AR. Time of Flight (ToF) sensors provide high accuracy but consume a significant amount of power due to active sensing (i.e., it emits a laser pulse and measures distance based on the return time). Our research reduces sensor power (i.e., on-time or number of pulses) and thus overall system power using lightweight algorithms that exploit temporal correlation to deliver real-time performance with minimal impact to depth map accuracy.
Related Publications: ICIP2017, ICIP2018, ICIP2019, TCSVT2020, arXiv2020
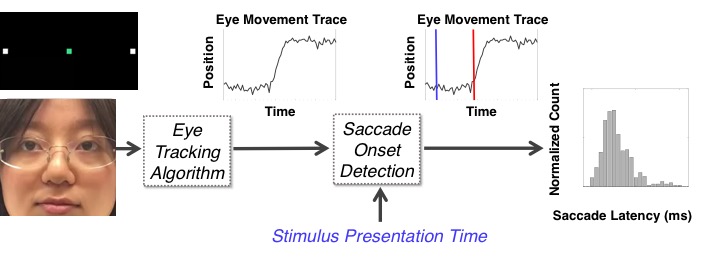
Mobile Health Monitoring
(In collaboration with Thomas Heldt)
According to the World Alzheimer’s Report, dementia affects 50 million people worldwide today and is expected to grow to 75 million in the next 10 years. Current methods of neuropsychological assessments require a trained specialist, which is time consuming and costly. Furthermore, repeat medical assessments are sparse, mostly qualitative/subjective, and suffer from high retest variability. It has been shown that eye movements (e.g., reaction time) can be used in conjunction with these assessments to quantitatively evaluate severity, progression or regression of neurodegenerative diseases. However, clinical measurements of eye movements are currently done in constrained environments and rely on specialized, costly equipment.
To address these limitations, we are developing a low-cost mobile platform to measure eye movement patterns. Measurements from the platform can tell researchers how well the patient’s brain is functioning, and be used to track disease progression in patients with neurodegenerative diseases such as Alzheimer’s or as an adjunct to clinical drug trials by making it easier to track improvements over time. The research challenge lies in how to replicate clinical grade measurements using low cost consumer grade cameras.
![]()
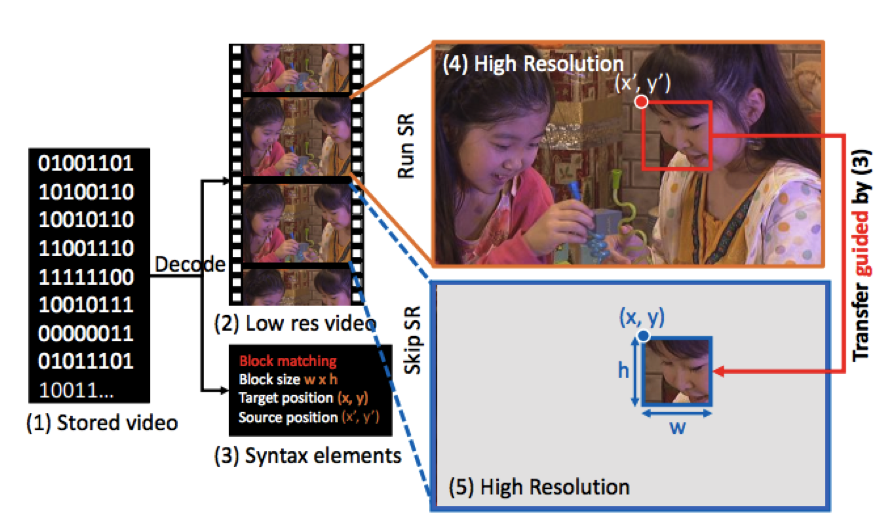

Accelerating Super Resolution with Compressed Video
Video resolutions can be limited due to the available content or limited transmission bandwidth. To improve the viewing experiences of low-resolution videos on high-resolution displays, super-resolution algorithms can be used to upsample the video while keeping the frames sharp and clear. Unfortunately, state-of-the-art super-resolution algorithms are computationally complex and cannot deliver the throughput required to support real-time upsampling of the low-resolution videos streamed from the cloud.
In this project, we develop FAST, a framework to accelerate any image based super-resolution algorithm by leveraging embedded information in compressed videos. FAST exploits the similarity between adjacent frames in a video. Given the output of a super-resolution algorithm on one frame, the technique adaptively transfers super-resolution pixels to the adjacent frames to avoid running super-resolution on those frames. The transferring process has negligible computation cost because the required formation including motion vectors, block size, and prediction residual are embedded in the compressed video for free. We show that FAST accelerates state-of-the-art super-resolution algorithms (e.g. SR-CNN) by up to an order of magnitude with acceptable quality loss up to 0.2 dB. FAST is an important step towards enabling real-time super-resolution on streamed videos for large displays.
Related Publications: CVPRW2017, arXiv2016
Please visit the project website for more info.
Download code here.

![]()
Next-Generation Video Coding Systems
Video is perhaps the biggest of the ‘big data’ being collected and transmitted. Today, over 500 million hours of video surveillance are collected every day, over 300 million hours of video are uploaded to YouTube every hour, and over 70% of the today’s Internet traffic is used to transport video. The exponential growth of video places a significant burden on global communication networks; thus video compression continues to be an important area of research. Next generation video compression systems must deliver not only higher coding efficiency, but also high throughput to support increasing resolutions, and low energy consumption as most video is captured on battery operated devices. We used joint design of algorithms and hardware in the development of the latest video coding standard, High Efficiency Video Coding (H.265/HEVC), which delivers 50% higher coding efficiency relative to its predecessor H.264/AVC, while at the same time increasing throughput and reducing energy consumption [Springer Book on HEVC]. The JCT-VC standards committee received the 2017 Primetime Engineering Emmy Award for the development of HEVC.
CABAC entropy coding was a well-known throughput bottleneck in H.264/AVC due to its highly serial nature with many feedback loops. We redesigned CABAC entropy coding for the H.265/HEVC standard to both increase coding efficiency, and to deliver higher throughput by reordering syntax elements and restructuring the context modeling to minimize feedback loops [TCSVT2012]. We then designed hardware that exploited these features such that our H.265/HEVC CABAC accelerator achieves 4x higher throughput than the fastest existing H.264/AVC CABAC accelerators, enough for Ultra-HD 8K at 120 fps [TCSVT2015]. Another advance is the use of large transforms in H.265/HEVC for higher coding efficiency. Larger transforms traditionally result in more computation and thus larger energy cost. We designed hardware that exploits the sparsity of the coefficients, such that the same energy is consumed per pixel regardless of the transform size [ICIP2014]. This approach may enable future video coding systems to use larger transforms for higher coding efficiency without impacting energy cost. Finally, to perform HEVC decompression on wearable devices, we proposed adaptive compression to reduce leakage of the embedded DRAM used for reference frame storage [JSSC2018].
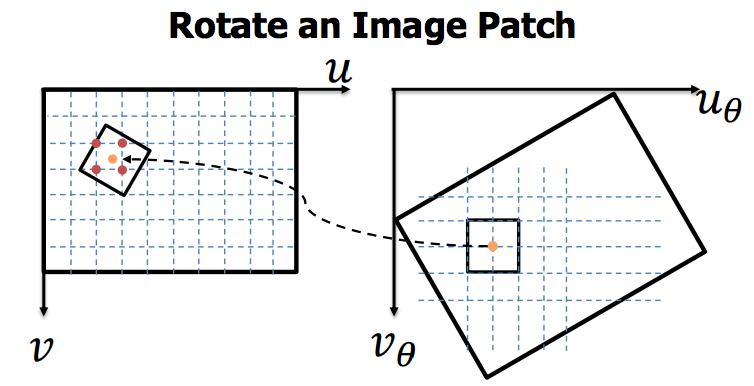
Finally, there is also a strong need for video coding tools beyond H.265/HEVC. In this project, we developed a new technique called Rotate Intra Block Copy, which utilizes the rotation invariant similarity between the patches in the same frame to improve intra block prediction, such that it provides coding gain to not only screen content, but all forms of video content. Combined with the existing predictor from HEVC, this technique gives an average of 20% reduction in residual energy. With a novel method to encode the intra motion vector, it achieves a coding gain in BD-rate of 3.4%. In practice, this technique can reduce the transmission bandwidth of the ultra-high-resolution video content [ICIP2015].
Related Publications: Springer Book on HEVC, TCSVT2012, TCSVT2015, JETCAS2013, ICIP2014, ICIP2015, VLSI2017, JSSC2018